Bing Spell Check Is Deprecated: What to Use Instead
- Azure
- Cloud
- Engineering
It is almost been a year since Microsoft pulled this plug, but the problem it forced me to think through has not gone stale. If anything it has gotten more relevant, because every deprecation notice right now points you toward the same fix: swap it for an LLM based service. Sometimes that is genuinely the right call. A lot of the time it is just what is shipping this quarter, and the cost bill shows up three months later when nobody is looking.
Microsoft retired the Bing Search APIs, including Spell Check, on August 11, 2025. If you were running a bot service that cleans user input before it hits your NLU layer, this probably broke something for you.
This is how we actually thought through the replacement. Not because our solution is the correct one, it has real tradeoffs I am not going to hide, but because the decision making process matters more than any specific stack. If you are a senior engineer being handed just replace the spell checker as a one line ticket, this is for you: it was never really a which library problem, it was a business constraints problem wearing a technical costume.
The setup
User messages went through a spell check pass before hitting the bot service. Small thing, big impact. Something like helo, I want too chnage my adress needed to become clean enough for the NLU model to classify with confidence. Bing Spell Check handled this well and we never had to think about it. Then Microsoft pulled the plug. We disabled the call rather than fail silently, intent recognition accuracy dropped, and someone above me said to fix it.
Doing what Microsoft tells you to do
Microsoft's own retirement notice points to Grounding with Bing Search, part of Azure AI Agent Service. It is built for RAG scenarios: an LLM decides whether to search, pulls live web data, generates a cited response. It is not a spell checker, it is a full search and answer pipeline that happens to be the migration path Microsoft wants.
If your actual need is take a string, fix typos, return it fast, this is architecturally the wrong tool.
- Latency is wrong. You are adding an LLM call plus a live search round trip to a step that used to return in milliseconds.
- Cost is wrong. Community pricing comparisons after the retirement showed the Grounding based path landing anywhere from roughly 40 percent to nearly 5 times more expensive than the old API, depending on volume. At chatbot scale, checking every inbound message, that compounds fast.
- The compliance surface changes. Your query and resource key leave the Azure compliance boundary, which is a security conversation, not a simple swap.
- It solves a different problem. You are normalizing noisy typing, not grounding an answer in live web data.
The LLM option is not wrong because LLMs are bad at spelling, GPT class models are decent at contextual correction. It is wrong because the economics do not match a task that runs on every message, forever.
The actual spectrum
Spell checking is not one technique, it is a spectrum, and where you land should be driven by business constraints, not by what is trending that week.
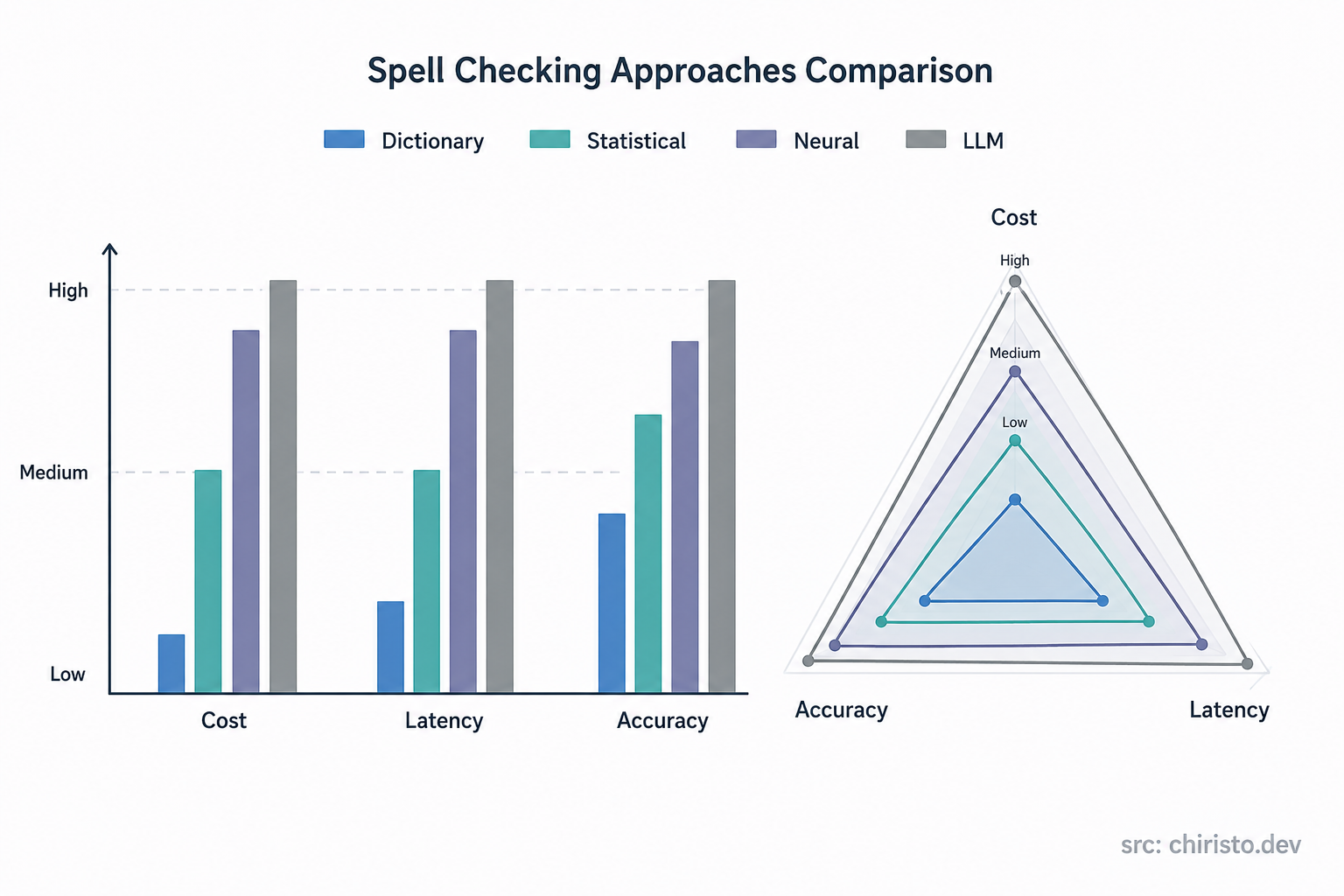
- Dictionary and edit distance (Hunspell, Aspell, SymSpell). Tokenize, look up, find the closest match by Levenshtein distance. Fast, cheap, zero concept of context, so it cannot tell there from their.
- Statistical language models, the ngram family. This traces to the noisy channel model formalized by Kernighan, Church and Gale, later extended by Mays, Damerau and Mercer. Instead of asking if a word is spelled right, you ask how likely it is given the surrounding words, trained on a probability table from a large corpus. Still statistical, not understanding, but context aware, and it runs on CPU with no per request inference cost.
- Neural and transformer based correction, toolkits like NeuSpell wrapping BERT, ELMo, or LSTM models. Published benchmarks often show these winning on recall, catching more errors, but ngram based approaches have shown higher precision in some head to head comparisons, meaning fewer wrong corrections at the cost of missing some real ones. That matters a lot when a confidently wrong correction is worse than a missed typo. You are also now hosting and serving a model, GPU cost included.
- LLM based correction sits at the far end. Best contextual understanding, most expensive, highest latency by a wide margin.
None of these is objectively best. Four points on a cost, latency, and accuracy curve, and the right one depends entirely on what you are building.
Where the real complexity showed up
- Domain vocabulary breaks generic dictionaries. Product and brand names get flagged as misspellings, so you end up owning an allow list and a data maintenance problem that used to belong to someone else.
- Edit distance alone makes bad guesses without context, which is exactly the gap a context layer exists to close.
- Entities are not words. URLs, emails, and order numbers need protection before correction and reassembly after, or you will correct someone's email into garbage.
- False positives cost differently than false negatives. Correcting a real product name into a dictionary word is often worse than leaving a typo alone. The goal shifts from maximize accuracy to minimize confidently wrong corrections, a precision first framing.
The pipeline shape, kept generic
The point here is not which language or database we used, it is that the shape is portable across any locale if you design it right.
- Preserve entities first, mask URLs, emails, and alphanumeric patterns, unmask them at the end.
- Tokenize while preserving structure so punctuation can be reconstructed after correction.
- Layered lookup: exact domain word, then dictionary, then fuzzy domain matching scaled by word length.
- Score ambiguous candidates against a context model built from that locale's corpus, with a fallback so a low confidence match still returns something useful.
- Smart punctuation handling, leaning on the same context layer so abbreviations do not get treated as sentence boundaries.
Swap the dictionary for a different locale, retrain the context model on that language's corpus, and the orchestration does not change. That portability was deliberate, once we realized we might need more than one market. I am deliberately not detailing the exact technique in that scoring layer, because the point of this post was never a blueprint to copy, it is the decision making underneath it.
Being honest about the tradeoffs
- The corpus itself is a storage and maintenance problem, trading per request inference cost for a dataset you have to build, host, and keep current.
- It is frequency based, not meaning based. It flags statistically unusual sequences, it does not understand the sentence the way a large language model can.
- Cold start for new domain vocabulary is real, a new product name has no history until you seed it in.
This is not the best architecture in some absolute sense, it is the best fit for high volume, a tight latency budget, a bias against confidently wrong corrections, and a cost ceiling that ruled out per request inference. Change any of those constraints and the right answer on the spectrum moves. That is the actual thesis: the constraints choose the tool.
The takeaway
When a vendor deprecates a utility and points you at their LLM based replacement, do not take it at face value just because it is the easy path. Ask what actually determines cost and correctness at your scale, not the demo's scale.
- Does the replacement fit your real latency budget?
- What is the per request cost at your actual volume?
- Does this need genuine reasoning, or fast pattern matching with some context bolted on?
- Is a wrong but confident output worse than a missed one for your users?
- What is your compliance posture on data leaving your boundary?
Everyone moving to LLM based solutions is a trend, not an architecture decision. The teams that get burned swap a component built for one purpose for a general purpose reasoning engine because it was first in the migration guide. The teams that get it right treat cost, latency, and error tolerance as top priority constraints from day one, and pick the point on the spectrum that actually matches the job.
Bing Spell Check being deprecated was not the hard problem. Figuring out what we actually needed a spell checker to do, at what cost and accuracy bar, was.
Comments
Enjoyed this one?
Subscribe to get posts like this straight to your inbox - no noise, just quality content.