What Is Load Balancing in System Design? Explained Simply
28 Apr 2026
- Engineering
- Architecture
- Learning
- Cloud
Let me pick up exactly where we left off.
Last time, we said horizontal scaling means adding more servers. Distribute the load. Add more cashiers to the supermarket.
But here's the question nobody asked how does the customer know which cashier to go to?
That's the job of a load balancer. And that's what this blog is about.
The Airport Check-In Analogy
Picture a busy airport. Hundreds of passengers arriving. Ten check-in counters open.
There's a friendly agent at the front, calmly directing each passenger to the right counter. No chaos. No guessing. Passengers move quickly. No single counter is drowning while others sit idle.
 Everything flowing smoothly. Each counter has just enough work.
Everything flowing smoothly. Each counter has just enough work.
Now imagine there is no directing agent. Every passenger just rushes to the first counter they see.
Counter 1 has 80 people in line. Counters 2 through 10 are empty. The agent at Counter 1 is overwhelmed. Flights are missed. People are furious.
 This is your system without a load balancer.
This is your system without a load balancer.
This is exactly what happens when horizontal scaling is done without proper traffic distribution.
Your servers are the counters. Your users are the passengers. And the load balancer is the directing agent at the front.
So What Is a Load Balancer?
A load balancer sits in front of your servers. Every user request hits the load balancer first. The load balancer then decides which server should handle that request, and forwards it there.
The user never knows which server responded. They just get their answer.
Simple concept. Massive impact.
Ok here's the next question. The load balancer is standing at the front. A request comes in. Five servers are waiting. How does it decide where to send it? There is no single answer. Different strategies exist, each with its own tradeoffs. Let's see the two most common ones.
Approach 1: Round Robin (Take Turns)
The simplest way to distribute traffic: take turns.
Request 1 -> Server A
Request 2 -> Server B
Request 3 -> Server C
Request 4 -> Server A again
...and so on.
Back to the airport every new passenger is directed to the next counter in a fixed rotation. Counter 1, Counter 2, Counter 3, Counter 1 again.
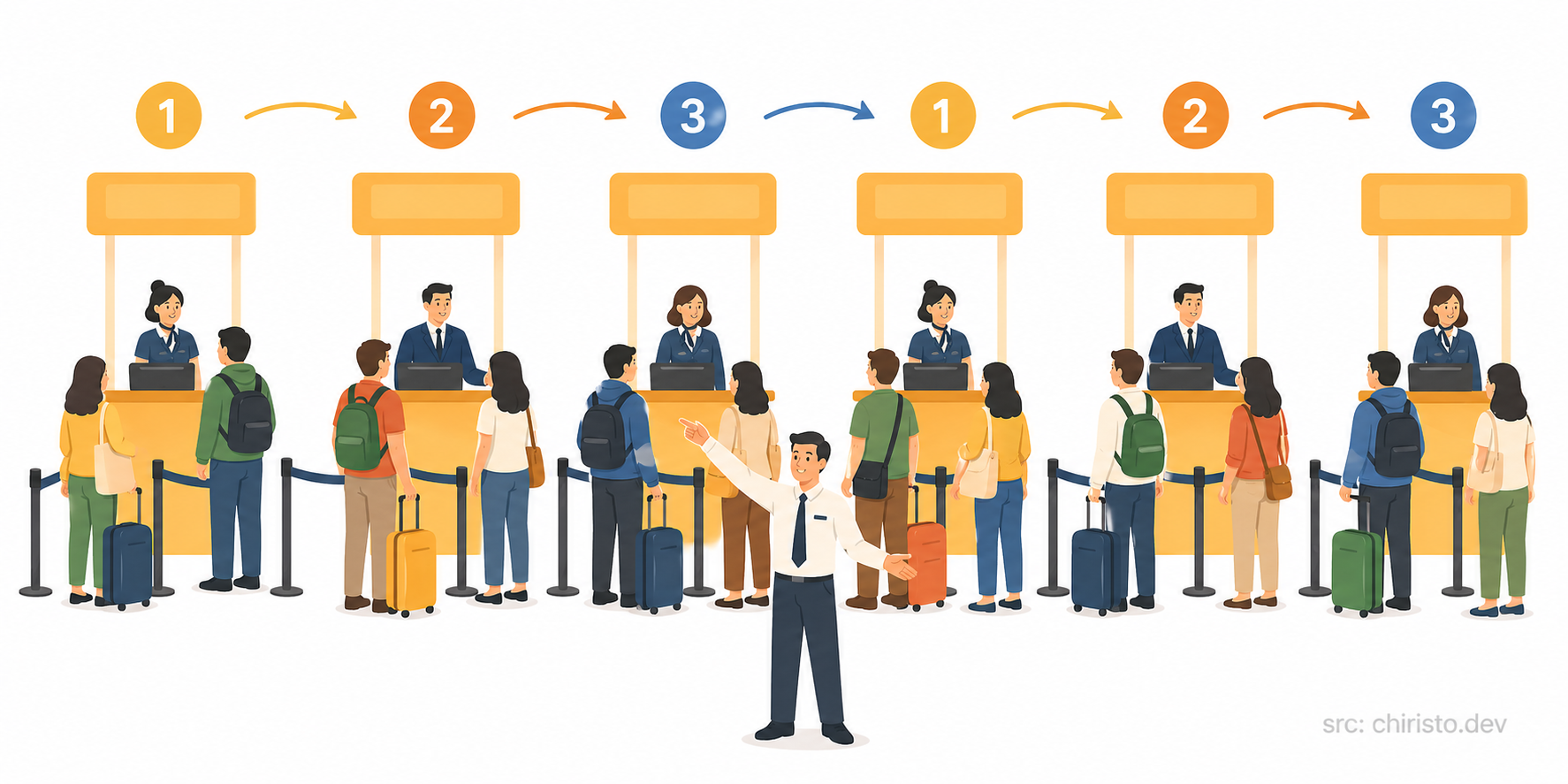 Fair on paper. But is it always fair in reality?
Fair on paper. But is it always fair in reality?
The upside: Dead simple. Works well when all requests take roughly the same time and all servers are equally capable.
The downside: What if one request takes 10 seconds and another takes 10 milliseconds? Round robin doesn't care. It keeps sending equally. One server could pile up with slow, heavy requests while another sits idle finishing quick ones in milliseconds.
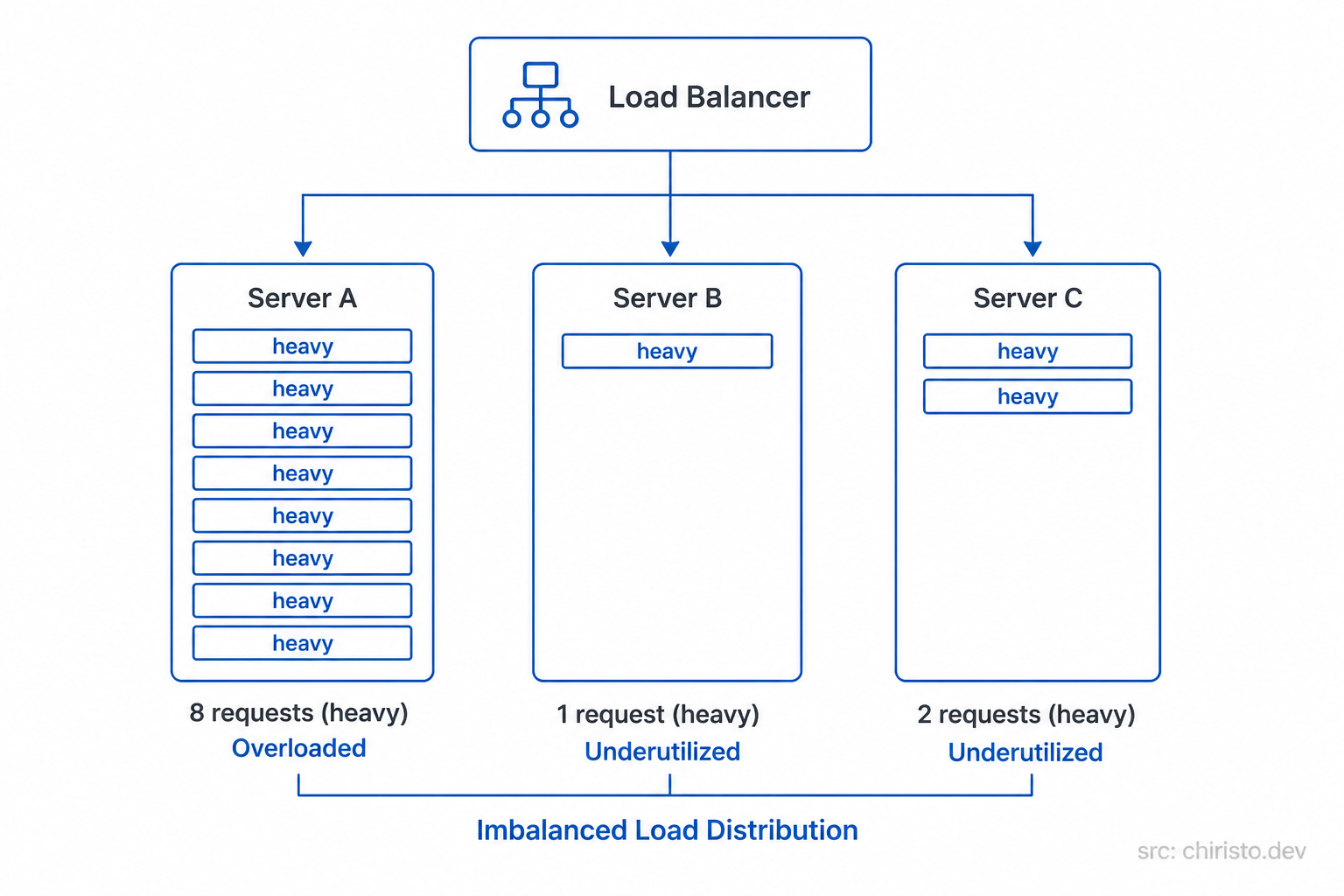 Equal distribution != equal load. This is the limit of pure round robin.
Equal distribution != equal load. This is the limit of pure round robin.
Approach 2: Least Connections (Go Where It's Quietest)
A smarter approach is to send the next request to whichever server is currently handling the fewest active requests.
Back to the airport, instead of rotating blindly, the agent looks at each counter in real time and sends the next passenger to whichever counter has the shortest active queue right now.
 The smarter agent. Looking before directing.
The smarter agent. Looking before directing.
The upside: Naturally handles uneven request durations. Servers doing heavy work get less new traffic until they catch up. Much more balanced in the real world.
The downside: Slightly more overhead than round robin. The load balancer has to track active connections per server at all times.
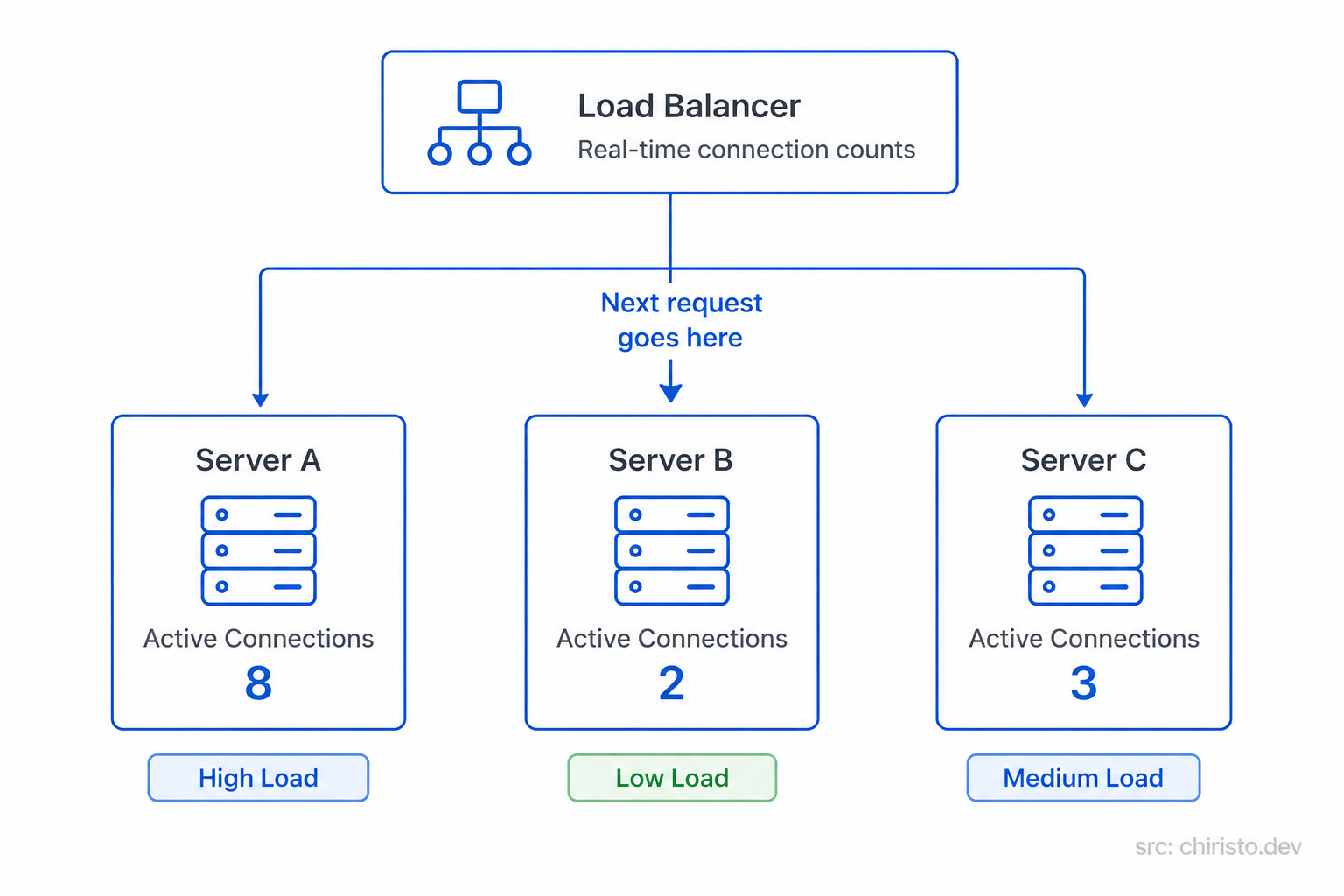 The load balancer sees the real picture. Not just who's next in line.
The load balancer sees the real picture. Not just who's next in line.
The Hidden Trap: Sticky Sessions
Here is something that trips up a lot of teams.
Some applications store data on the server itself like a logged-in session. User logs in on Server A. Next request goes to Server B. Server B has no idea who this user is. They're suddenly logged out.
This is the sticky session problem.
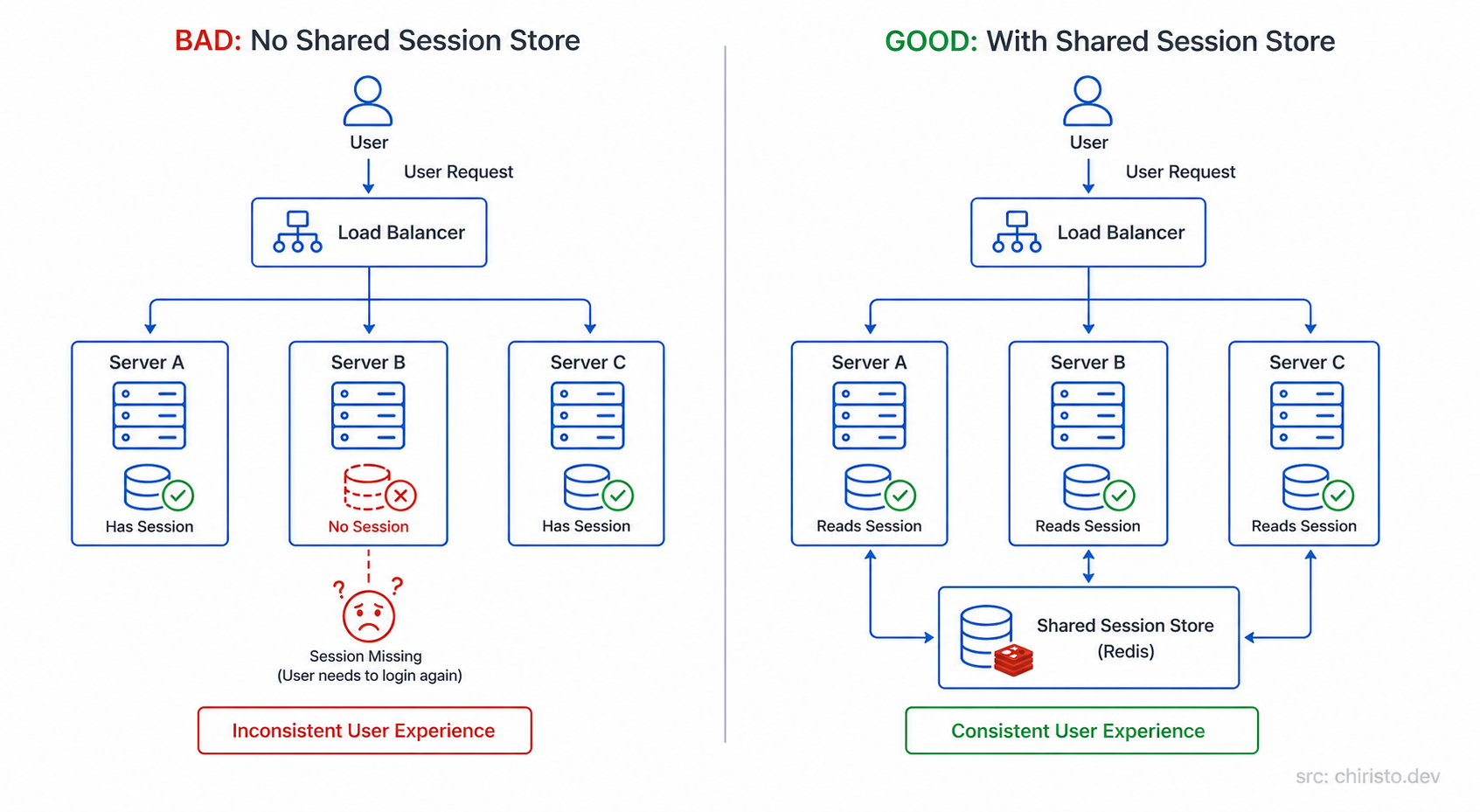 Left - sessions break. Right - sessions live in a shared store, not on individual servers.
Left - sessions break. Right - sessions live in a shared store, not on individual servers.
There are two ways to handle this
Option 1 - Sticky sessions (IP Hash): The load balancer always routes requests from the same user to the same server. Problem solved, but now you've created an uneven distribution. One server might get all the heavy users.
Option 2 - Stateless servers + shared session store: The better approach. Keep your servers stateless. Store sessions in a central layer (like Redis) that every server can access equally. This is the correct pattern for horizontal scaling.
This is the exact same hidden trap from the scalability blog. Horizontal scaling requires stateless design. Load balancers surface that requirement immediately.
Generic Cloud Architecture - No AWS. No GCP. No Azure.
This is how a properly load-balanced system looks like in pure architecture terms
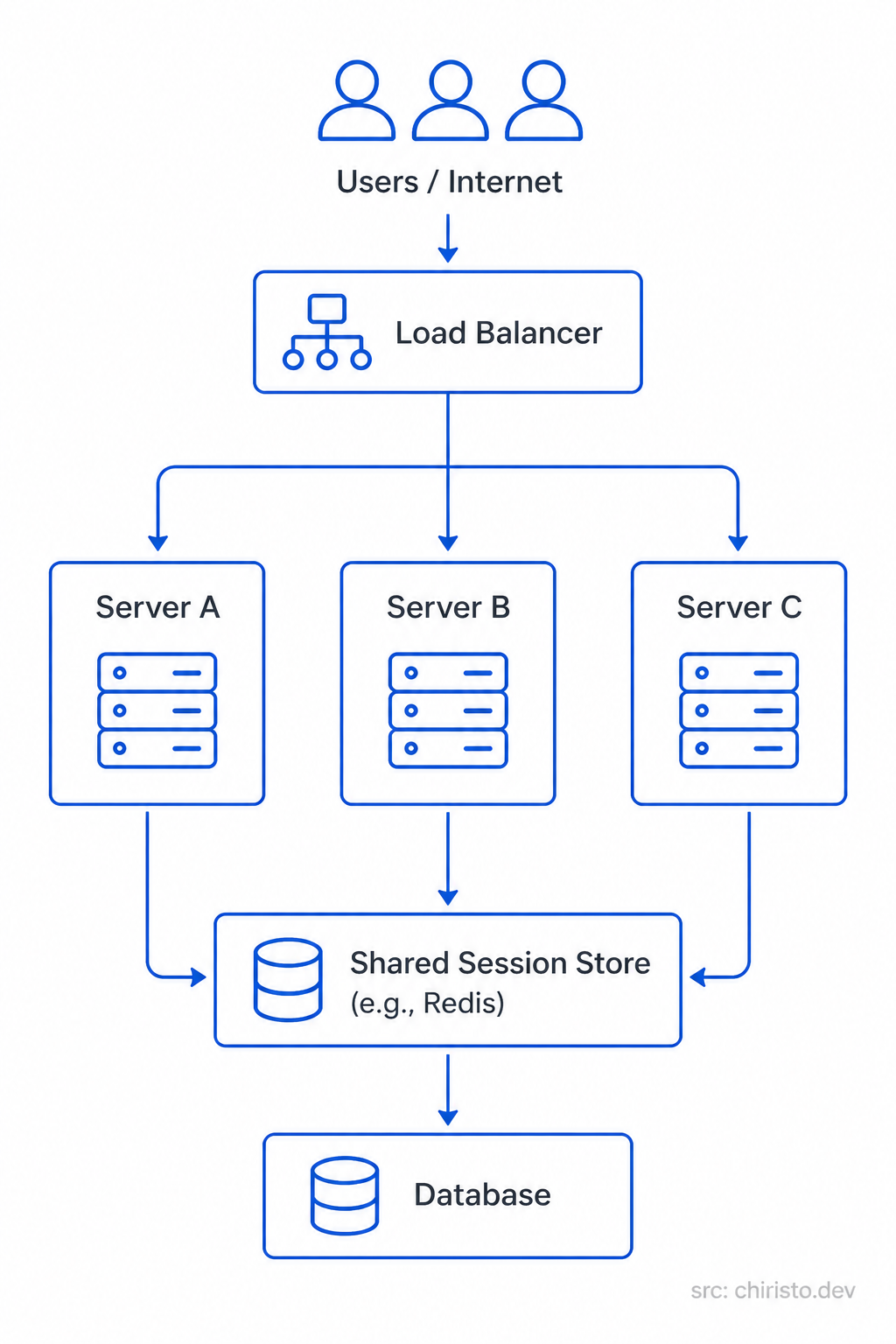 One entry point. Many servers. One shared state layer. This is the pattern.
One entry point. Many servers. One shared state layer. This is the pattern.
Every user request enters through the load balancer. The load balancer picks a healthy, available server. The server handles the request, reads/writes shared state if needed, and responds. The user sees none of this complexity. They just get a fast response.
The load balancer also does health checks by continuously pinging each server. If a server stops responding, the load balancer stops sending traffic to it automatically. The system heals itself.
How This Looks on AWS, GCP, and Azure
The same pattern. Different names.
| Component | AWS | GCP | Azure |
|---|---|---|---|
| Load Balancer | Application Load Balancer (ALB) | Cloud Load Balancing | Azure Load Balancer / Front Door |
| Server Instances | EC2 (in Auto Scaling Group) | Compute Engine (in MIG) | Azure VMs (in VM Scale Set) |
| Shared Session Store | ElastiCache (Redis) | Memorystore | Azure Cache for Redis |
| Health Checks | Built into ALB Target Groups | Built into Cloud LB Backend Services | Built into Azure Load Balancer Probes |
Same architecture. Same logic. Just different service labels. Once the pattern clicks, you can read any cloud diagram.
Quick Recap
- A load balancer sits in front of your servers and distributes incoming requests.
- Round Robin rotates traffic evenly simple but doesn't account for request weight.
- Least Connections routes to the server with fewest active requests smarter for real-world traffic.
- The sticky session trap is real solve it by keeping servers stateless and using a shared session store.
- Load balancers do health checks and automatically stop sending traffic to unhealthy servers.
- All major clouds implement the same pattern with different service names.
What's Next?
Your system now distributes traffic across servers. Requests are handled in parallel. Failures are recovered automatically.
But what if the same data is being fetched from the database thousands of times per second? Reading the same user profile, the same product page, the same config over and over.
That's a different kind of bottleneck. And that's exactly what Caching solves.
See you in the next one.
Stay curious. Build better systems.